这篇文章主要介绍了Python爬虫解析网页的4种方式实例及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
用Python写爬虫工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情。"text-align: center"> "text-align: center">
"text-align: center">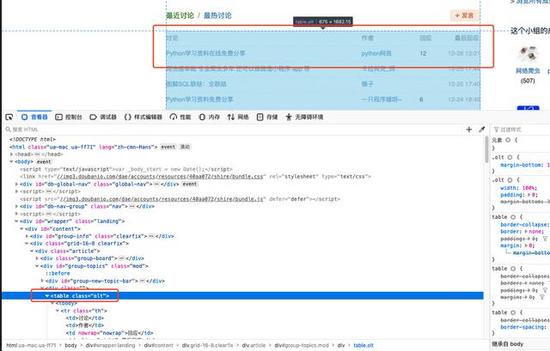 "text-align: center">
"text-align: center"> "htmlcode">
"htmlcode">
rl = 'https://www.douban.com/group/491607/'headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则的好处是编写麻烦,理解不容易,但是匹配效率很高,不过时至今日有太多现成的HTMl内容解析库之后,我个人不太建议再手动用正则来对内容进行匹配了,费时费力。
主要解析代码:
re_div = r'<table\s+class=\"olt\">[\W|\w]+</table>'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'<a .*?>(.*"<a.*", str(content), re.I|re.S|re.M)
2: requests-html
这个库其实是我个人最喜欢的库,作则是编写requests库的网红程序员 Kenneth Reitz,他在requests的基础上加上了对html内容的解析,就变成了requests-html这个库了。
下面我们来看看范例:
 "text-align: left">我喜欢用requests-html来解析内容的原因是因为作者依据帮我高度封装过了,连请求返回内容的编码格式转换也自动做了,完全可以让我的代码逻辑简单直接,更专注于解析工作本身。
"text-align: left">我喜欢用requests-html来解析内容的原因是因为作者依据帮我高度封装过了,连请求返回内容的编码格式转换也自动做了,完全可以让我的代码逻辑简单直接,更专注于解析工作本身。
主要解析代码:
links = response.html.find('table.olt', first=True).find('a')
安装途径: pip install requests-html
3: BeautifulSoup
大名鼎鼎的 BeautifulSoup库,出来有些年头了,在Pyhton的HTML解析库里属于重量级的库,其实我评价它的重量是指比较臃肿,大而全。
还是来先看看代码。
 "htmlcode">
"htmlcode">
soup = BeautifulSoup(response, 'html.parser')links = soup.findAll("table", {"class": "olt"})[0].findAll('a')
BeautifulSoup解析内容同样需要将请求和解析分开,从代码清晰程度来讲还将就,不过在做复杂的解析时代码略显繁琐,总体来讲可以用,看个人喜好吧。
安装途径: pip install beautifulsoup4
4: lxml的XPath
lxml这个库同时 支持HTML和XML的解析,支持XPath解析方式,解析效率挺高,不过我们需要熟悉它的一些规则语法才能使用,例如下图这些规则。
 "htmlcode">
"htmlcode">
content = doc.xpath("//table[@class='olt']/tr/td/a")
 "text-align: left">如上图,XPath的解析语法稍显复杂,不过熟悉了语法的话也不失为一种优秀的解析手段,因为。
"text-align: left">如上图,XPath的解析语法稍显复杂,不过熟悉了语法的话也不失为一种优秀的解析手段,因为。
安装途径: pip install lxml
四种方式总结
正则表达式匹配不推荐,因为已经有很多现成的库可以直接用,不需要我们去大量定义正则表达式,还没法复用,在此仅作参考了解。
BeautifulSoup是基于DOM的方式,简单的说就是会在解析时把整个网页内容加载到DOM树里,内存开销和耗时都比较高,处理海量内容时不建议使用。不过BeautifulSoup不需要结构清晰的网页内容,因为它可以直接find到我们想要的标签,如果对于一些HTML结构不清晰的网页,它比较适合。
XPath是基于SAX的机制来解析,不会像BeautifulSoup去加载整个内容到DOM里,而是基于事件驱动的方式来解析内容,更加轻巧。不过XPath要求网页结构需要清晰,而且开发难度比DOM解析的方式高一点,推荐在需要解析效率时使用。
requests-html 是比较新的一个库,高度封装且源码清晰,它直接整合了大量解析时繁琐复杂的操作,同时支持DOM解析和XPath解析两种方式,灵活方便,这是我目前用得较多的一个库。
除了以上介绍到几种网页内容解析方式之外还有很多解析手段,在此不一一进行介绍了。
写一个爬虫,最重要的两点就是如何抓取数据,如何解析数据,我们要活学活用,在不同的时候利用最有效的工具去完成我们的目的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
免责声明:本站资源来自互联网收集,仅供用于学习和交流,请遵循相关法律法规,本站一切资源不代表本站立场,如有侵权、后门、不妥请联系本站删除!
《魔兽世界》大逃杀!60人新游玩模式《强袭风暴》3月21日上线
暴雪近日发布了《魔兽世界》10.2.6 更新内容,新游玩模式《强袭风暴》即将于3月21 日在亚服上线,届时玩家将前往阿拉希高地展开一场 60 人大逃杀对战。
艾泽拉斯的冒险者已经征服了艾泽拉斯的大地及遥远的彼岸。他们在对抗世界上最致命的敌人时展现出过人的手腕,并且成功阻止终结宇宙等级的威胁。当他们在为即将于《魔兽世界》资料片《地心之战》中来袭的萨拉塔斯势力做战斗准备时,他们还需要在熟悉的阿拉希高地面对一个全新的敌人──那就是彼此。在《巨龙崛起》10.2.6 更新的《强袭风暴》中,玩家将会进入一个全新的海盗主题大逃杀式限时活动,其中包含极高的风险和史诗级的奖励。
《强袭风暴》不是普通的战场,作为一个独立于主游戏之外的活动,玩家可以用大逃杀的风格来体验《魔兽世界》,不分职业、不分装备(除了你在赛局中捡到的),光是技巧和战略的强弱之分就能决定出谁才是能坚持到最后的赢家。本次活动将会开放单人和双人模式,玩家在加入海盗主题的预赛大厅区域前,可以从强袭风暴角色画面新增好友。游玩游戏将可以累计名望轨迹,《巨龙崛起》和《魔兽世界:巫妖王之怒 经典版》的玩家都可以获得奖励。
更新日志
- 群星《前途海量 电影原声专辑》[FLAC/分轨][227.78MB]
- 张信哲.1992-知道新曲与精丫巨石】【WAV+CUE】
- 王翠玲.1995-ANGEL【新艺宝】【WAV+CUE】
- 景冈山.1996-我的眼里只有你【大地唱片】【WAV+CUE】
- 群星《八戒 电影原声带》[320K/MP3][188.97MB]
- 群星《我的阿勒泰 影视原声带》[320K/MP3][139.47MB]
- 纪钧瀚《胎教古典音乐 钢琴与大提琴的沉浸时光》[320K/MP3][148.91MB]
- 刘雅丽.2001-丽花皇后·EMI精选王【EMI百代】【FLAC分轨】
- 齐秦.1994-黄金十年1981-1990CHINA.TOUR.LIVE精丫上华】【WAV+CUE】
- 群星.2008-本色·百代音乐人创作专辑【EMI百代】【WAV+CUE】
- 群星.2001-同步过冬AVCD【环球】【WAV+CUE】
- 群星.2020-同步过冬2020冀待晴空【环球】【WAV+CUE】
- 沈雁.1986-四季(2012梦田复刻版)【白云唱片】【WAV+CUE】
- 纪钧瀚《胎教古典音乐 钢琴与大提琴的沉浸时光》[FLAC/分轨][257.88MB]
- 《国语老歌 怀旧篇 3CD》[WAV/分轨][1.6GB]